情感分析用词语集-语文情感词
时间:2024-11-25人气: 作者:佚名
咱们现在这数据时代,情感分析这事挺关键,可就是缺了点素材,这成了做情感分析的一大难题。虽然SnowNLP模块能干情感挖掘的活儿,但它主要就是用淘宝那边的评论素材,这就让咱们用起来不能光靠它,得好好优化优化。
语料缺乏问题
在情感分析这块儿,资料不够用真是挺让人头疼的。好多时候咱们一动手搞情感分析,结果发现资料不够丰富。比如说,一个新领域的项目,根本找不到相应的大规模语料。可能是在一家新成立的数据挖掘公司,一个刚进来的数据分析员碰上这事,想做到准确的情感分析可就挺难的。
SnowNLP是个挺有用的工具。它是用淘宝的评论数据来做情感分析的,不过因为数据量不大,所以在做文本分析的时候不一定能完全准确。特别是对于来自其他领域或者特定情境下的文本,有时候就会出现误差。
文本需要特别处理
用SnowNLP做情感分析,文本处理这块儿特别关键。得把常见的停用词给去掉,还得考虑词性啥的。比如,看一篇科技产品的评测文章,那文章可能就是新产品刚出来那时候写的,写的也是各个评测员的不同看法。要是只简单地去掉停用词,好多有用的信息就给漏掉了。
而且,不同词性的词汇在表达情感时作用各异。比如,形容词往往能直接体现情感倾向。但若仅删除无情感的词汇,诸如那些在语法中连接词句但自身并无情感意义的词,那可能就没能妥善处理那些带有情感倾向的实词。
长文本的应对之策
处理超长文本可得讲究方法,尤其是面对那些冗长的新闻报道或学术论文。若直接用SnowNLP来分析,很可能会因为资料覆盖不全和特征工程不到位等问题,使得分析结果不够精确。
s.sentiment
提取关键词或者先进行文本摘要再提取关键词,这其实是个挺靠谱的办法。就拿一篇讲某上市公司年度报告的大文章来说,它讲的是公司总部的事情,涉及到好几个高层和普通员工,这种文章先做个摘要,SnowNLP就能更准确地抓住里面的主要情感和信息。
实践中的结果差异
举个例子,比如这条头条文章《5分钟11亿,京东双11场景化产品消费增长明显》,内容看起来挺积极的。可要是只用SnowNLP来分析,结果只给0.5分,这显然不太对劲。不过,要是我们先从文本里提取出关键词,然后再进行分析,得出的结果就靠谱多了。
举个例子,有些长篇文字经过各种不同的处理手段,得出的结果差异挺大的。比如在某个购物高峰期,不同的处理方法在这种情况下的区别就特别明显。
机器学习的局限
s.sentiment
**而抽取关键词后,得分0.8 符合**
SnowNLP主要用贝叶斯机器学习方法来训练文本,但这方法有它的短板。因为机器学习在语料上可能不够全面,一些新兴的网络流行语这样的特殊文本,可能就没能被涵盖进去。
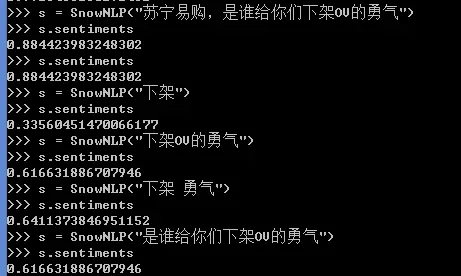
处理特征工程若不当,分数会降低,还忽略了语义。就拿“苏宁易购,你们哪来的胆子把OV给撤了?”这样的文本来说,‘下架’才是关键,它表达了愤怒。但用SnowNLP常规分析,结果就偏了,因为它没考虑到语义层面的因素。
语义层面不可忽略
在情感分析领域,语义的重要性可不能小觑。就拿“苏宁易购,这OV的爱情****怎么就给下架了?”这样的例子来说,因为语义本身就挺复杂的,要是光用老办法分析,那结果很可能就错了。假设这是产品调整的时候,涉及到的人可能是消费者或者运营人员,语义可是直接影响到大家对整个句子情感倾向的判断。
做情感分析可得深挖语义,不然得出的结果跟实际情况可是差远了。
踊跃提问,大家在进行情感分析时是否遇到过类似SnowNLP这样的问题,结果因为种种原因不准确?不妨留言交流,期待大家的互动。同时,若觉得这篇文章对您有帮助,别忘了点赞和转发!