语音情感识别rnn-情感语音识别研究
时间:2025-03-15人气: 作者:佚名
这语音情感识别,听起来挺牛的,其实就是教机器分辨你的心情。你一嗓子,它就明白你怒了;你一笑,它也跟着乐。再过几年,说不定连你那装出来的笑它都能识破。
语音情感识别的基本概念
机器听你说话,能从那声音里头看出你心情的好坏。这东西主要分两招:一招是把情绪像切豆腐似的分成愤怒、高兴、兴奋、难过、讨厌这些;另一招,就是看情绪的甜咸和活跃度。听起来挺高大上,其实就是教机器怎么通过你的话来猜你脸色。
梅尔倒谱系数的重要性
搞语音情感识别这事,绕不开梅尔倒谱系数这东西。这东西是处理语音信号时提取特征的高手,主要任务是挖出跟情感扯上关系的特征。简单来说,它就像是语音的“指纹”,机器就是靠这个“指纹”来猜你心情的。
CASIA语音情感数据库
搞语音情感分析,数据那是核心。CASIA汉语情感语料库,这名字挺响亮的,里面存了9600条各种情绪的语音。这语音是四个演员录的,一共六种情绪:怒火中烧、乐呵呵、提心吊胆、伤心欲绝、大吃一惊和正常。还有300条是同一句话,但情绪不一样,研究起来方便得很,看看情绪变化对声音的影响。
模型训练与过拟合问题
搞定了数据,得开始练手模型了。咱们用那啥卷积神经网络(CNN)来试试语音情感识别,效果还挺给力的。可到了60轮训练,模型就开始跟咱们玩儿过家家了,训练的时候精度能到70%,可验证的时候就掉到50%了。这不就是跟考试似的,你刷题刷多了,题目越做越熟,换了个新题型,直接懵圈了。
实际应用与未来展望
这语音情绪识别技术,将来能派上用场的地儿可不少。比如说,它能帮你弄个智能客服,让那机器根据你心情来变服务招数;再比如在教育圈,它能根据学生心情来调整教学方法。这技术要是真能火起来,说不定你家那狗都能听懂你心情了。
%matplotlib inline
import librosa
import matplotlib.pyplot as plt
import numpy as np
path=r'D:\NLP\dataset\语音情感\test.wav'
y,sr = librosa.load(path,sr=None)
def normalizeVoiceLen(y,normalizedLen):
nframes=len(y)
y = np.reshape(y,[nframes,1]).T
#归一化音频长度为2s,32000数据点
if(nframes
res_data=np.zeros([1,res],dtype=np.float32)
y = np.reshape(y,[nframes,1]).T
y=np.c_[y,res_data]
else:
y=y[:,0:normalizedLen]
return y[0]
def getNearestLen(framelength,sr):
framesize = framelength*sr
#找到与当前framesize最接近的2的正整数次方
nfftdict = {}
lists = [32,64,128,256,512,1024]
for i in lists:
nfftdict[i] = abs(framesize - i)
sortlist = sorted(nfftdict.items(), key=lambda x: x[1])#按与当前framesize差值升序排列
framesize = int(sortlist[0][0])#取最接近当前framesize的那个2的正整数次方值为新的framesize
return framesize
VOICE_LEN=32000
#获得N_FFT的长度
N_FFT=getNearestLen(0.25,sr)
#统一声音范围为前两秒
y=normalizeVoiceLen(y,VOICE_LEN)
print(y.shape)
#提取mfcc特征
mfcc_data=librosa.feature.mfcc(y=y, sr=sr,n_mfcc=13,n_fft=N_FFT,hop_length=int(N_FFT/4))
# 画出特征图,将MFCC可视化。转置矩阵,使得时域是水平的
plt.matshow(mfcc_data)
plt.title('MFCC')
冷幽默的语音助手
想象下,将来那语音小能手不仅能听你哔哔哔,还能一眼看穿你那假笑。你嘴上说着“我挺好”,它却来一句“别装了,听你那语气,明显是生气呢”。这货的冷笑话,估计得让不少人笑中带泪。
如何让机器“懂你”
#提取特征
import os
import pickle
counter=0
fileDirCASIA = r'./语音情感/CASIA database'
mfccs={}
mfccs['angry']=[]
mfccs['fear']=[]
mfccs['happy']=[]
mfccs['neutral']=[]
mfccs['sad']=[]
mfccs['surprise']=[]
mfccs['disgust']=[]
listdir=os.listdir(fileDirCASIA)
for persondir in listdir:
if(not r'.' in persondir):
emotionDirName=os.path.join(fileDirCASIA,persondir)
emotiondir=os.listdir(emotionDirName)
for ed in emotiondir:
if(not r'.' in ed):
filesDirName=os.path.join(emotionDirName,ed)
files=os.listdir(filesDirName)
for fileName in files:
if(fileName[-3:]=='wav'):
counter+=1
fn=os.path.join(filesDirName,fileName)
print(str(counter)+fn)
y,sr = librosa.load(fn,sr=None)
y=normalizeVoiceLen(y,VOICE_LEN)#归一化长度
mfcc_data=librosa.feature.mfcc(y=y, sr=sr,n_mfcc=13,n_fft=N_FFT,hop_length=int(N_FFT/4))
feature=np.mean(mfcc_data,axis=0)
mfccs[ed].append(feature.tolist())
with open('mfcc_feature_dict.pkl', 'wb') as f:
pickle.dump(mfccs, f)
语音情感识别这东西虽然进步神速,但要让机器真懂你,还得过五关斩六将。你说,怎么让这机器在各种场合都能玩转?怎么让它精准识别情绪这复杂东西?这俩问题,得好好琢磨琢磨。
%matplotlib inline
import pickle
import os
import librosa
import matplotlib.pyplot as plt
import numpy as np
from keras import layers
from keras import models
from keras import optimizers
from keras.utils import to_categorical
#读取特征
mfccs={}
with open('mfcc_feature_dict.pkl', 'rb') as f:
mfccs=pickle.load(f)
#设置标签
emotionDict={}
emotionDict['angry']=0
emotionDict['fear']=1
emotionDict['happy']=2
emotionDict['neutral']=3
emotionDict['sad']=4
emotionDict['surprise']=5
data=[]
labels=[]
data=data+mfccs['angry']
print(len(mfccs['angry']))
for i in range(len(mfccs['angry'])):
labels.append(0)
data=data+mfccs['fear']
print(len(mfccs['fear']))
for i in range(len(mfccs['fear'])):
labels.append(1)
print(len(mfccs['happy']))
data=data+mfccs['happy']
for i in range(len(mfccs['happy'])):
labels.append(2)
print(len(mfccs['neutral']))
data=data+mfccs['neutral']
for i in range(len(mfccs['neutral'])):
labels.append(3)
print(len(mfccs['sad']))
data=data+mfccs['sad']
for i in range(len(mfccs['sad'])):
labels.append(4)
print(len(mfccs['surprise']))
data=data+mfccs['surprise']
for i in range(len(mfccs['surprise'])):
labels.append(5)
print(len(data))
print(len(labels))
#设置数据维度
data=np.array(data)
data=data.reshape((data.shape[0],data.shape[1],1))
labels=np.array(labels)
labels=to_categorical(labels)
#数据标准化
DATA_MEAN=np.mean(data,axis=0)
DATA_STD=np.std(data,axis=0)
data-=DATA_MEAN
data/=DATA_STD
接下来保存好参数,模型预测的时候需要用到。
paraDict={}
paraDict['mean']=DATA_MEAN
paraDict['std']=DATA_STD
paraDict['emotion']=emotionDict
with open('mfcc_model_para_dict.pkl', 'wb') as f:
pickle.dump(paraDict, f)
技术进展中的挑战
这语音情感识别技术,它的发展路上可真是不平坦。你说这数据集,它质量一差,模型效果就跟着受影响,可问题是好数据集又不好找。再说了,这识别的准确性还得往上提,特别是在那些情绪复杂的时候,得让机器更懂人心。
ratioTrain=0.8
numTrain=int(data.shape[0]*ratioTrain)
permutation = np.random.permutation(data.shape[0])
data = data[permutation,:]
labels = labels[permutation,:]
x_train=data[:numTrain]
x_val=data[numTrain:]
y_train=labels[:numTrain]
y_val=labels[numTrain:]
print(x_train.shape)
print(y_train.shape)
print(x_val.shape)
print(y_val.shape)
未来研究的方向
未来的语音情感研究,估计要往多感官结合的方向发展。就是说,得把说话的声调、脸上的表情、身体的动作这些东西都拼凑起来,这样才能更准地猜出人家心里啥滋味。就跟咱们平时聊天一样,不光听人咋说,还得观察人家是啥表情,啥动作,综合起来判断个大概。
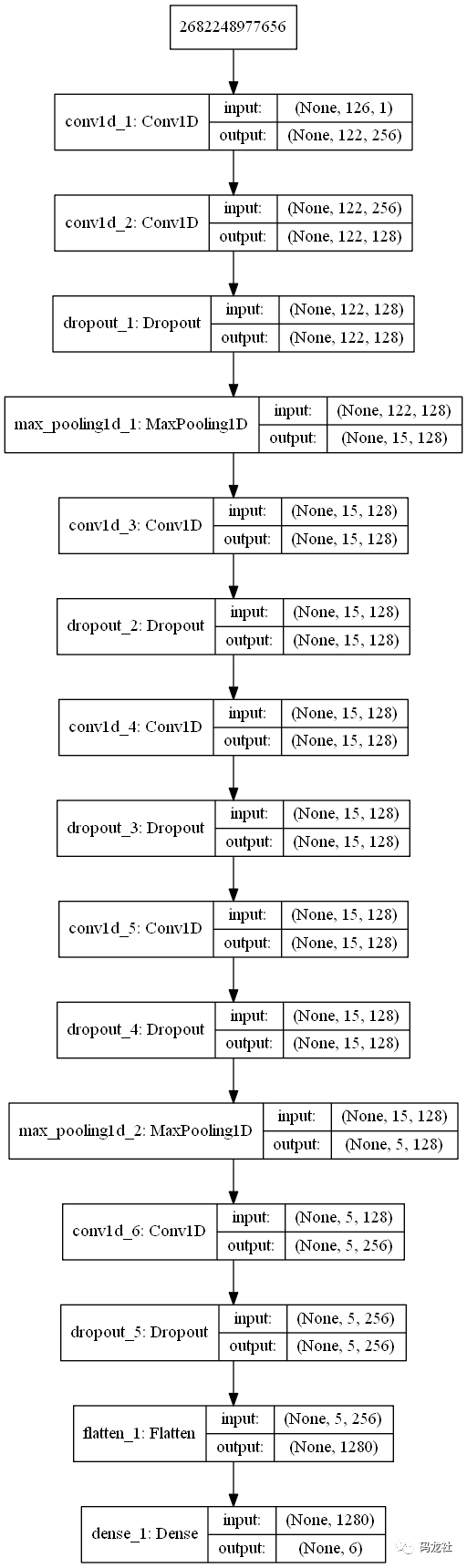
from keras.utils import plot_model
from keras import regularizers
model = models.Sequential()
model.add(layers.Conv1D(256,5,activation='relu',input_shape=(126,1)))
model.add(layers.Conv1D(128,5,padding='same',activation='relu',kernel_regularizer=regularizers.l2(0.001)))
model.add(layers.Dropout(0.2))
model.add(layers.MaxPooling1D(pool_size=(8)))
model.add(layers.Conv1D(128,5,activation='relu',padding='same',kernel_regularizer=regularizers.l2(0.001)))
model.add(layers.Dropout(0.2))
model.add(layers.Conv1D(128,5,activation='relu',padding='same',kernel_regularizer=regularizers.l2(0.001)))
model.add(layers.Dropout(0.2))
model.add(layers.Conv1D(128,5,padding='same',activation='relu',kernel_regularizer=regularizers.l2(0.001)))
model.add(layers.Dropout(0.2))
model.add(layers.MaxPooling1D(pool_size=(3)))
model.add(layers.Conv1D(256,5,padding='same',activation='relu',kernel_regularizer=regularizers.l2(0.001)))
model.add(layers.Dropout(0.2))
model.add(layers.Flatten())
model.add(layers.Dense(6,activation='softmax'))
plot_model(model,to_file='mfcc_model.png',show_shapes=True)
model.summary()
结语:机器的“情感”
opt = optimizers.rmsprop(lr=0.0001, decay=1e-6)
model.compile(loss='categorical_crossentropy', optimizer=opt,metrics=['accuracy'])
import keras
callbacks_list=[
keras.callbacks.EarlyStopping(
monitor='acc',
patience=50,
),
keras.callbacks.ModelCheckpoint(
filepath='speechmfcc_model_checkpoint.h5',
monitor='val_loss',
save_best_only=True
),
keras.callbacks.TensorBoard(
log_dir='speechmfcc_train_log'
)
]
history=model.fit(x_train, y_train,
batch_size=16,
epochs=200,
validation_data=(x_val, y_val),
callbacks=callbacks_list)
model.save('speech_mfcc_model.h5')
model.save_weights('speech_mfcc_model_weight.h5')
这语音识别技术,还在成长期,可潜力大得吓人。将来,机器不仅能听明白你说的啥,还能猜到你心里啥滋味。要是这技术真能玩得溜,保不齐得让大家又惊喜又惊慌。
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()




