微博情感分析研究现状-现状微博情感研究分析报告
时间:2025-04-13人气: 作者:佚名
现在连发个微博都得让机器来把你的情绪给分析一遍,这世道矫情都得让AI给识破。2012年NLP和CC评测的数据显示,机器识别微博观点的准确度已经把人给比下去了,以后咱们得先过算法这一关再发牢骚。
中文微博的三大难题
微博这东西,分分钟就能产出上万条新鲜东西,要人工去盯着,那简直就像用吸管去喝太平洋的水。专家们发现,难点主要在三个地方:得先分出哪些句子是在发表观点,然后还得判断这观点是夸还是骂,最后还得找出具体是夸啥骂啥。比如说,"这家火锅店服务真差"这句话,机器得先识别出这是在发表观点,然后判断出是负面情绪,还得精确地指出是在吐槽"服务"这块儿。
新词识别有多难
网上的新词更新速度,比女友换脸还快,那些“绝绝子”、“yyds”之类的,老词库都追不上趟。一群研究的小伙伴弄了个多级词库,用频率统计抓新词。他们发现,“蚌埠住了”这类词在微博上出现的频率像坐火箭一样飙升,可“芜湖起飞”就短暂闪现了一下。看样子,网络流行语也是有保质期的。
观点句识别玄学
感叹号虽常见,却未必全在陈述看法。"说今天天气真好",这算观点,可"iPhone13要发布了"这就不一样了。算法这东西,得靠分析词儿和它们评价的对象啥的来辨别人家啥意思,好比"演技炸裂"这俩词儿一起出现,多半是在夸演员。可要是碰上"这操作真下饭"这种阴阳怪气的,机器有时候也得懵圈。
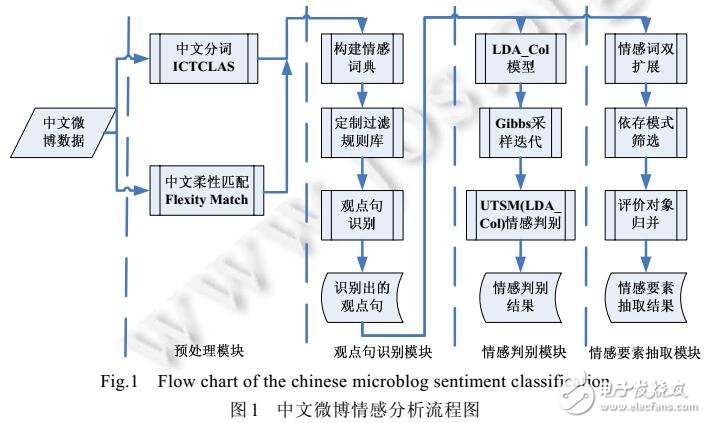
情感分类黑科技
专家们弄了个LDA-Collocation模型,说白了就是研究词语怎么摆。好比“价格公道”和“良心被狗咬”,俩词都有“良心”,但感觉差远了。吉布斯抽样能抓到这小细节,可碰上“这操作大气层”这种搞笑话,机器就得蒙圈了。
要素抽取的优先级
这算法,为了找茬吐槽,给依存模式排了个六档优先级。像“客服态度差劲”这种,比“被客服气得半死”好分析多了。可碰上“建议把书名改为《重生之我在美团送外卖》”这种高级黑,就算规则再复杂,也招架不住。
实战检验结果
这NLP&CC2012比拼里,咱这系统在观点识别上排第二,要素提取那F值也第二。有意思的是,这东西处理速度比人快了200倍,可要是碰上“地铁老人看手机.jpg”这种纯图微博,直接就蔫了。想完全取代人工,机器还得加把劲,再修炼几年。
这事挺逗的:要是你发现发个微博都得让AI给你来个情感分析,你是打算低调点还是故意来点暗语,逗逗那个算法玩儿?






