情感词典 知网-知网情感词典百度云
时间:2024-10-13人气: 作者:佚名
上节课咱们聊了怎么用SnowNLP工具给评论的情感来个快速扫描。今儿咱们来深挖下另一种流行的情感分析法——就是靠情感词典来分析。这招主要是捡出文本里的情感关键词,然后根据这些词的“感情值”判断全文的大致情绪倾向。现在,咱们常用的情感词典有BosonNLP的和知网出的。
BosonNLP情感词典的基本介绍
波森NLP出的那本情感词典,是波森自然语言处理公司搞的。里面的每个情绪词都有个对应的情绪分,是正、负还是零,意思就是积极、消极或没差。用这个词典搞情感分析,先得把文本拆句又分词,通常得靠jieba分词工具来帮忙。
分词搞定了,得跟BosonNLP那个情感词典对对儿。每个对上的词都记着,还得看它词典里的评分。最后把这些词的分数加起来,就能看出这文本是啥情绪了。分数要是正的,那就积极;要是个负的,那就消极。
BosonNLP情感词典的匹配过程
弄BosonNLP那个情感词典做心情分析,合不吻合那一步很重要。头先,得分词搞准确,这直接影响后面匹配的准头。用那个jieba分词工具挺多人喜欢,它挺能干地将文章切成一个个字儿。
分词做完后,得一个一个把词和那个BosonNLP情感词簿对上号。每对上一个就得记下来,然后根据词簿上的情感点数给它打分。得特别注意簿子上情感词的分量,想办法多对上些。全对上后,把分数加总,就这样能看出这段话的情绪是啥样子的。
BosonNLP情感词典的评分汇总
好了,匹配完了得把那些情感词的得分加起来,这事儿不算难,就是把分数一一点拢就得了。
评分这事儿看起来容易,可是得留心细节。像有些带强烈情感的词,它们在总分里的分量挺重的。所以,咱们得特别盯着那些情感爆棚的词儿,保证能对得上号。

BosonNLP情感词典的优缺点
这BosonNLP情感词典,是做情感分析的利器,有几个大优点。第一,用起来真简单,就是分词、找关键词、评分这么三步走。第二,这个词典里的情感词汇挺全的,能识别大部分常见的情绪词。
不过,BosonNLP那个情感词库有点不完美。它涵盖挺多情感词汇,但也有可能会落下一些。再就是,它的情感评分是死的,不能根据说话的情境来变化。这样,有时候分析出来的情绪就不那么准了。
知网情感词典的基本介绍
除了BosonNLP那个情感词典,知网的也是挺常用的。跟BosonNLP的那个差不多,都是通过给情感词打分来判断文章啥感觉。不过,知网的那个在情感词的多少和打分上可能有点区别。
咱们用知网情感词典来分析文本情感,得先分词、对词匹配,最后把匹配上的词分数加起来。分词就用jieba分词软件,词词对照知网词典。把分数加总,就能看出这文章的整体情绪是啥样了。
知网情感词典的匹配过程
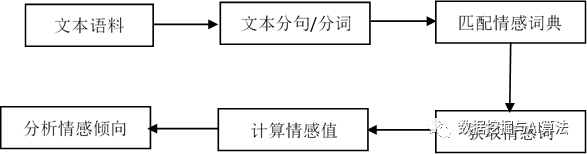
用知网情感词典做情感分析,那个匹配环节也是个挺重要的步骤。
分词做好后,咱们得把每个词跟知网的情感词典核对一遍。
知网情感词典的评分汇总
知网情感词典的优缺点
知网那个情感词典,咱们常用的情感分析工具,有几个很明显的好处。其中,它对情感词汇的收录挺全的,大部分常见的情感词都能对上号。
不过,知网那情感词库还是有缺点的。再者说,里面的情感分是死板的,不能根据话儿的情境来变。
咱们在实际操作时,得看具体情况,挑个合适的情感词典来做情感分析。不管是BosonNLP的还是知网的,都挺简单,能帮咱们快速准确看出文本啥情绪。这对我后面分析决策帮可大了。
# -*- coding:utf-8 -*-import pandas as pdimport jieba#基于波森情感词典计算情感值def getscore(text): df = pd.read_table(r"BosonNLP_dict\BosonNLP_sentiment_score.txt", sep=" ", names=['key', 'score']) key = df['key'].values.tolist() score = df['score'].values.tolist()# jieba分词 segs = jieba.lcut(text,cut_all = False) # 计算得分 score_list = [score[key.index(x)] for x in segs if(x in key)]return sum(score_list)#读取文件def read_txt(filename):with open(filename,'r',encoding='utf-8')as f: txt = f.read()return txt#写入文件def write_data(filename,data):with open(filename,'a',encoding='utf-8')as f: f.write(data)if __name__=='__main__': text = read_txt('test_data\文本语料.txt') lists = text.split('\n')# al_senti = ['无','积极','消极','消极','中性','消极','积极','消极','积极','积极','积极',# '无','积极','积极','中性','积极','消极','积极','消极','积极','消极','积极',# '无','中性','消极','中性','消极','积极','你觉得在实际用起来,哪款情感词典更适合做情感分析?来评论区说说你的想法,也给这文章点个赞,转发一下!



